In the first article of this series, I addressed the most impactful finding of a MIT Gen AI study, which was that, while most interviewed enterprises were struggling to leverage generative AI in productive use-cases, these companies’ own employees reported successfully integrating LLMs in their own day-to-day work. Additionally, I argued that the key challenge for such companies was to prepare for success in a world where leading AI research labs were already on path to profitability - implying that any generative AI use-cases they would build on top of SOTA models could be cannibalized by the labs themselves.
In this post, I will now list the key anti-pattern in my mind that’s a consequence of shallow product thinking in the world of LLMs and autonomous agents. I will also, based on my understanding of this anti-pattern, make my case for why context-heavy and domain-specific flywheel building is the real unlock for product companies.
Everyone was Wrong About the Interface
Soon after the consumer mainstreaming of ChatGPT and Claude apps had taken place, two prognostications started crystallizing in product circles around enterprise AI -
- while the model-core might be intelligent, the chat-only interface must be a limitation for some use-cases, and
- while the model might be eloquent, there’s value in extending its knowledge beyond the training data to bring to it up-to date world information.
Over the course of the next couple of years since 2023, both these notions seemed to fall flat, albeit due to different misreading of the development curves.
In relation to the chat-only interface, customers, including engineers in enterprises spoke loud and clear in their propensity to adjust their workflows to the text interface, rather than shunning the tools due to a lack of integration into existing enterprise work-horses, e.g. MS Excel or Salesforce. If anything, the enterprise SaaS vendors found themselves flat-footed when trying to get the same users to adopt shabbily bolted-on GPT wrappers onto their interfaces, who quickly found a new home in Claude artifacts, because it was never as much about the interface but the intelligent core itself.
Then there were the packaged “AI-native” vector databases sold as the enterprise search solutions that also missed the point: it turns out that agentic systems using BM25 but built close to the business logic layer can match or outperform pure vector search at scale, at a fraction of the migration+operational cost of vector databases all while being extremely flexible, understandable, and extensible, i.e. actually taking search seriously.
Forget the Model, Build the Context
All of that to say that the intelligent core is the only indispensable unit. So, how can a plucky startup even begin to create an LLM core to surpass general ones from the world-leading labs? The answer is - they don’t have to.
What they need is a context engine that grows over time, and a mechanism to "pattern match" on the growing context at inference time.
Agents allow an arbitrary level of control over a company-specific workflow AND validation steps necessary to get a particular job done. While designing such workflows might be trivial, creating a flywheel of continuous learning “on the job” is the real unlock.
The best way to understand this pattern is to first make sense of its anti-pattern, i.e. what not to do. Shallow product thinking, one written without a real persona in mind, will quickly settle at a product offering (or if you’re really unlucky - a drag-and-drop graph UX) where
- the atomic sub-agents are so generic that they now have only a distant relationship to your user’s day job. Example - PDF extraction agent
- the users are now in total control of how the sub-agents should be composed to actually accomplish a task.
By the fact of being both generic and infinitely composable, you lose the ability to tightly integrate a feedback loop into your context engine (because, context engine of which agent?) and, therefore, can never build a flywheel of improvement and user satisfaction.
As any good product manager will attest - to delight users, it is not enough to paint with broad strokes but really focus on a few user personas that really obsess you. And the way to delight these few personas is to think of (and encode) the jobs that they really have to do, instead of the smallest atomic units to get there.
Let’s make this proposal concrete with an example agentic workflow that sees its capabilities compound over time.
SOC2 compliance agent for mid-size scale-ups
A B2B SaaS company (~200 employees, Series C) is preparing for its first SOC 2 Type II examination, having already undergone an ISO 27001 audit the previous year. The CISO has four weeks, a two-person security team, and a stack of 100+ policy documents, risk assessments, and evidence artifacts from last year’s audit.
What the workflow-builder approach looks like
Atomic agents serving as building blocks:
- Document classifier — sorts all the 100+ documents into categories (policies, procedures, evidence, risk registers)
- Control mapper — maps ISO 27001 controls to SOC 2 criteria, resulting in a cross-reference matrix
- Gap finder — compares current policy documents against control requirements, flags missing keywords
- Evidence checker — verifies that each control has at least one linked evidence artifact
The expectation is that the platform user (CISO) can build their own workflow using the building blocks. The output of a typical built workflow: a multi-page cross-reference matrix with hundreds of ISO controls mapped to some SOC 2 criteria, some “gaps” flagged, and a final list of criteria requiring evidence. The CISO now has to manually verify every gap, figure out which ones are real, and address those with new evidence.
What the job-level agent actually does
The fundamental misunderstanding is that the job of the CISO is “map controls and find gaps.” However, their job actually is: produce an audit-ready evidence package that shows exactly what’s covered, what’s missing, and what needs remediation before the audit.
We transfer therefore the core workflow of a CISO into “agentic” units as follows:
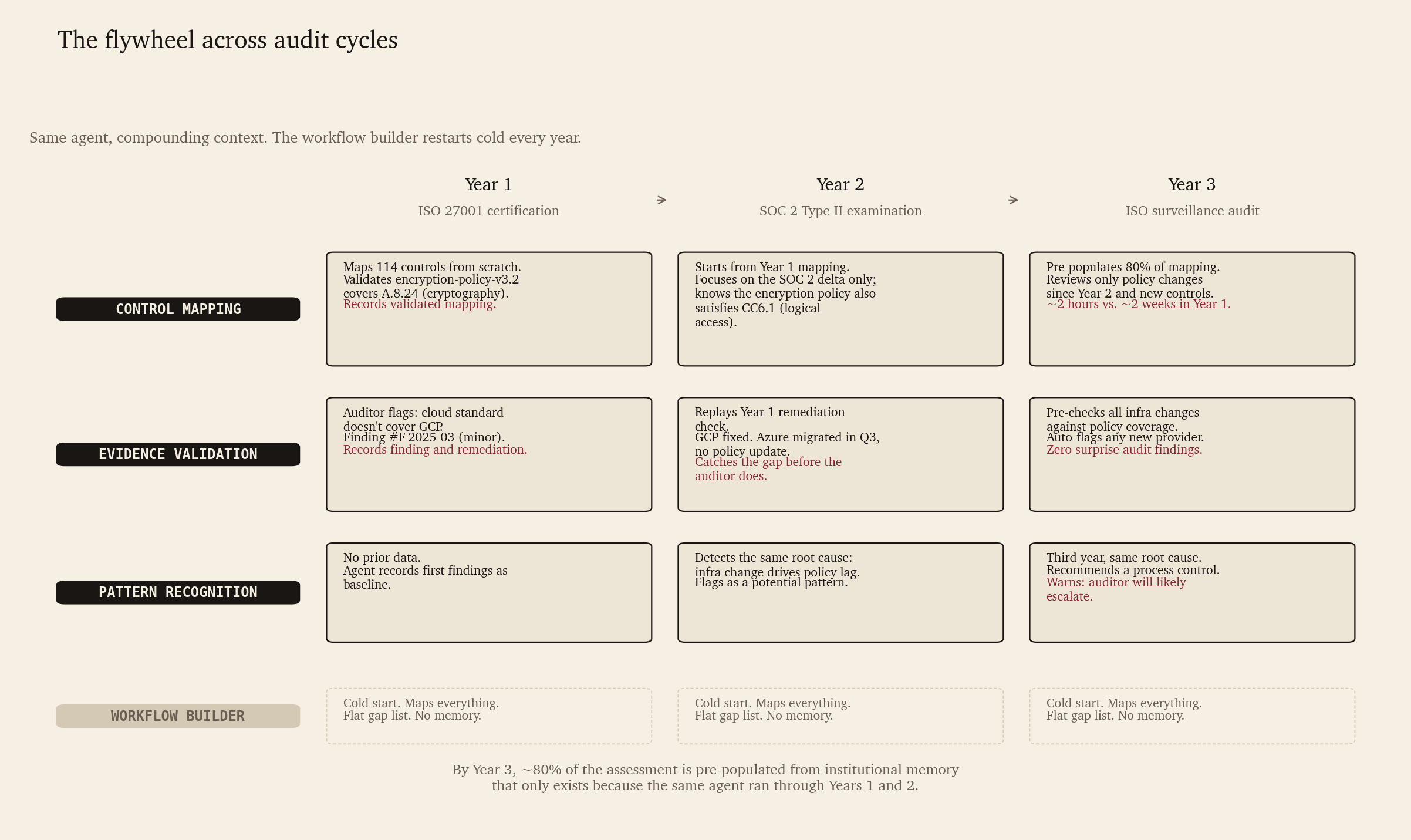
Step 1 — Control mapping with contextual understanding (not keyword matching)
The agent loads last year’s ISO 27001 control mapping as its starting point. It already knows, e.g., that one of the available documents was used as evidence for cryptography control, and was validated by the auditor. Therefore, instead of re-mapping all the ISO 27001 controls from scratch, it only asks “what has changed functionally from last year’s ISO audit?”
- If the change is in the policy document itself, that’s the only delta that needs to be handled by the agent.
- If the change is in the SOC2 criteria definition, such that it cannot be mapped to existing and audited ISO 27001 controls, that’s a new requirement in terms of documentation that the agent should flag.
A job agent designed in this way will build an improving flywheel of up-to date document evidence for both audits, and gets more and more useful over next audits. An atomic agent using embeddings for classification, on the other hand, will likely miss the fact that the document “Use of Cryptography” from ISO 27001 audit can also fulfil the SOC2 criteria of “Logical access security”.
Step 2 — Validation of evidence
While the workflow builder will check if each ISO 27001 control has a linked evidence - and map the evidence to the corresponding SOC2 criteria, it will miss the remediation applied on any gaps during last year’s audit because there’s no “learning from experience” involved.
A job-level agent won’t just check for what’s missing. Instead, for every linked evidence that was flagged for remediation last time, it has recorded
- the fact that it was flagged by the auditor
- the remediation applied to clear it
The agent then tries to replay the remediation step pro-actively. E.g. Say, last year’s audit flagged a Github repo not having dependabot or another vulnerability scanner turned on. If, since last year’s ISO 27001 audit, there have been new repos created in the account, a job-level agent will double check if dependabot is enabled for those before the auditor arrives. This builds another flywheel that strengthens the agentic system the more it gets employed.
Step 3 — Prioritized remediation plan
While the gap-finder step of workflow builder does produce a flat list of gaps, it doesn’t prioritize the gaps at all, other than having a rough estimate of the step-level difficulty.
A job-level agent, on the other hand, prioritizes the gap list, ranking those items higher that pattern-match recurring gap(s) from past audits, or those that, when fixed, would simultaneously address multiple gaps in SOC2 criteria. E.g. If since the last audit GCP was added as a new CSP to the stack, then the job-level agent will flag cloud security standard gap as “CRITICAL”, just because it remembers from past audits that a similar gap on Azure was flagged by the auditor.
Job-level agents are already at an advantage by this step, as they have gathered a contextualized list of gaps compared to an atomic agent. As you can see from this concrete example, a job-level agentic system, while requiring upfront investment in encoding real workflows, compounds its value over time and makes itself indispensable at a time when all the chatter is about replacing CRUD SaaS applications with “vibe-coded” in house alternatives.
Closing the Arbitrage Gap
When employees report that they’re using commercial chatbots at their own expense, it’s clear that it is the intelligent core of the chatbots that they’re after - not a GUI. The big chasm between individual-level and enterprise-wide adoption is the reliability of an experienced employee - the drag-and-drop workflow builder is never going to close it. It’s the tricky decisions that enterprise employees make that don’t follow a rule-book, but are nonetheless their own kind of implicit pattern, how employees make themselves indispensable, not the amount of time they spend grunt working through documents. If the product roadmap choice is between - a workflow builder UI with “atomic” agentic steps offered as building blocks vs. consciously sketching out core workflows, the shortcut of the former is not a wise choice at all.
Encoding step-by-step decision processes, tasks and transformations as agentic logic, but crucially also tracing actual workflow runs in practice, recording all unsuccessful workflow runs and manual overrides to inform subsequent decisions gives the builder an unmatched context engine that keeps their customers from churning.
Build what Compounds
The moat is a continuously learning system of domain-specific decision patterns that no competitor can replicate without running through the same volume of real cases. In building with AI in 2026, your product is either getting measurably smarter with every interaction, or it’s a feature waiting to be vibe-coded away.